League of Legends is team-based game where players form a team of five and assume the role of a champion -
characters with varying types of classes and unique abilities - and battle against another team of five players.
ARAM (All Random, All Mid) is a special game mode where the game randomly assigns champions to each player instead of the
player selecting his own.
As mentioned, in the game lobby, each player starts with a randomly assigned champion, but is able to re-roll in order to obtain
a new champion (the previous champion can be re-selected).
Thus, the goal of this app is to predict the best combination of champions that would lead to a win. The game client attempts to make as
random as possible, with each team with a probability to win of 50%. However, certain combinations of champions are likely to have
synergistic effects, and others might have antagonistic effects.
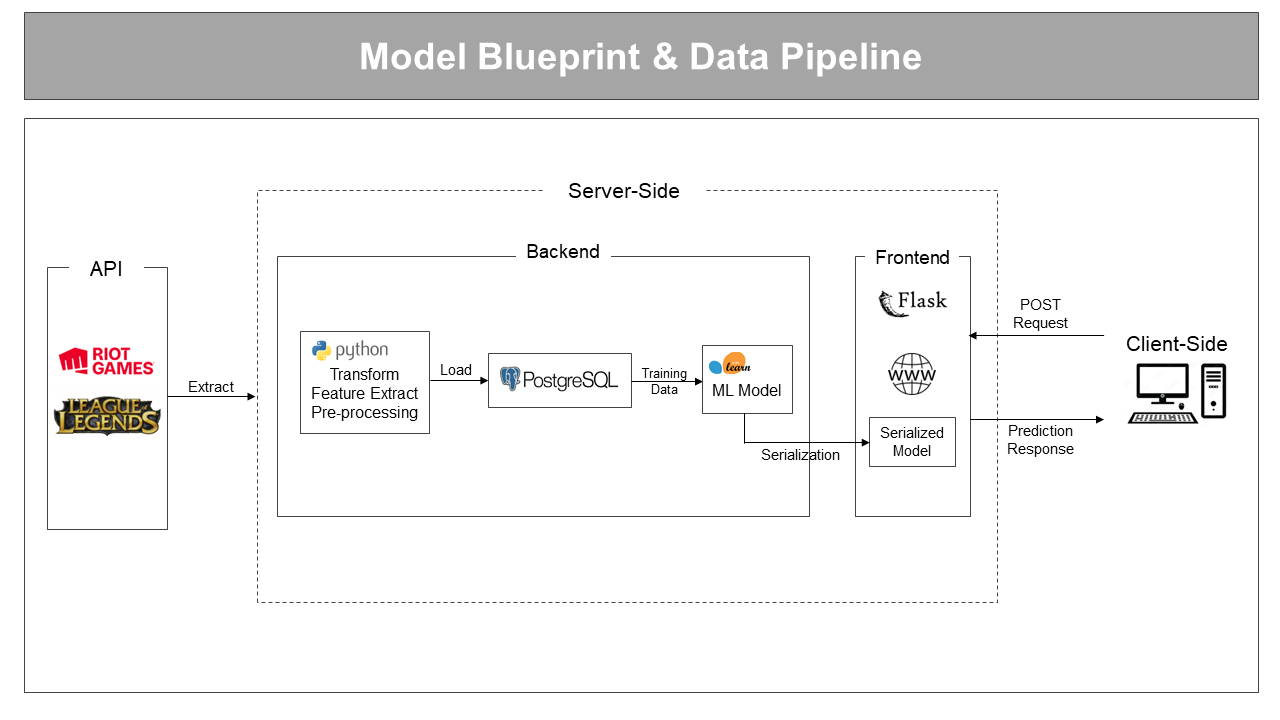
For each of the dropdown option, select the champion for each of the teammates and press submit to post the data into the backend. The data is sent into the serialized ML model, which outputs the predicted probabilities for a Victory.